

촉촉한초코칩
Machine Learning 2 본문
https://developers.google.com/machine-learning/crash-course?hl=ko
검증 세트
검증세트 : 다른 파티션
1. 가능한 워크플로

- 학습 데이터 : 모델 학습
- 테스트 데이터 : 테스트 후 측정 항목 관찰 > 속성 추가/제거를 통해 모델 정확성 개선
- 모델 조정 : 학습률 변경, 특성 추가 또는 삭제, 완전히 새로운 모델 설계 등 모델의 모든 요소를 조정하는 것
> 워크플로의 끝에서 테스트 세트를 기준으로 가장 우수한 모델 선택
문제점 : 테스트 데이터만의 특성에 과적합한 모델이 나온다면?
해결 방법 : 모집단에서 3번째 데이터 만들기 > 테스트 데이터는 사용 X > 좋은 결과가 나올 때까지 계속 반복
2. 데이터 세트 하나를 3개의 하위 집합으로 슬라이싱

- 검증 세트를 사용하여 학습 세트의 결과 평가
- 모델이 검증세트 통과 후 테스트 세트를 사용하여 평가 다시 확인
3. 워크플로 개선

- 검증세트에서 가장 우수한 결과를 보이는 모델 선택
- 테스트 세트를 기준으로 모델 다시 확인
표현
특성 추출
1. 특성 추출을 통해 원시 데이터를 ML 특성에 매핑

- 특성 추출 : 원시 데이터를 특성 벡터로 변환하는 과정
- 머신러닝 모델은 특성 값에 모델 가중치를 곱해야 하므로 특성을 실수 벡터로 표현해야 한다.
2. 정수 값을 부동 소수점 값에 매핑 : 숫자값 매핑

정수, 부동 소수점 데이터 > 인코딩 X
3. 원-핫 인코딩을 통한 상세 주소 매핑 : 범주형 값 매핑
- 범주형 특성 : 가능한 값의 이산 집합을 가짐
ex) {'Charleston Road', 'North Shoreline Boulevard', 'Shorebird Way', 'Rengstorff Avenue'}
> 특성 추출을 사용하여 문자열을 숫자 값으로 변환 - 어휘로 지칭할 특성 값을 정수로 매핑
> 데이터 세트의 모든 거리를 OOV(어휘 범위 외) 버킷이라고 하는 포괄적인 '기타' 카테고리로 그룹화 - 이름을 숫자로 매핑하는 방법
> 위 예시를 첫번째부터 0, 1, 2, ... 그 외 모든항목(OOV)을 4로 매핑 - 문제점 : 제약 조건 발생
> 모델은 거리마다 서로 다른 가중치를 학습할 수 있어야 함
> 가중치는 다른 특성을 사용하여 추정한 가격에 더해짐
해결 방법 : 모델의 범주형 특성마다 다음과 같이 값을 나타내는 바이너리 벡터 생성
- 예시에 적용되는 값의 경우 해당하는 벡터 요소를 1로 설정
- 다른 요소는 모두 0으로 설정
- 원-핫 인코딩 : 단일 값이 1일 때
- 멀티-핫 인코딩 : 여러 값이 1일 때

- 위 그림에서는 집이 Shorebird Way이므로 해당 경우에만 1이다. 따라서 모델은 해당 경우의 가중치만 사용한다.
- 집이 두 거리가 만나는 모퉁이에 있는 경우에는 2개의 2진수 값이 1로 설정되며 모델은 각각의 가중치를 모두 사용한다.
* 희소 표현
- 데이터의 개수가 1,000,000개 있다고 가정할 때, 요소 1개 또는 2개만 true로 이루어져있다면 1,000,000개로 이루어진 바이너리 벡터를 명시적으로 만드는 것은 비효율적이다.
- 이때는 0이 아닌 값만 저장되는 희소 표현을 사용한다.
좋은 특성 > 벡터 내에서 어떤 종류의 값이 실제로 좋은 특성을 만드는가
거의 사용되지 않는 불연속 특성값 피하기
- 좋은 특성 값 : 약 5회 이상 표시되어야 함 > 특성값이 라벨과 어떻게 관련되는지 학습할 수 있음
- 특성 값이 한 번만 표시되거나 매울 드물게 나타나는 경우 > 모델이 학습할 수 없어 예측 불가능
house_type : victorian > house_type 특성에는 값이 victorian인 예가 많이 포함됨명확한 의미 선호
- 좋은 특성 값 : 명확한 이름이 있으며 값은 이름의 의미와 관련되어 있다.
- 경우에 따라 엔지니어링 선택이 아니라 노이즈가 많은 데이터로 인해 불분명한 값이 발생할 수 있음
'특수' 값을 실제 데이터와 혼용하지 말 것
- 좋은 부동 소수점 특성 : 특이한 범위를 벗어난 불연속 값이나 '매직'값이 포함되지 않음
#해당 예시는 어떤 특성이 0과 1 사이의 부동 소수점 값을 가지고 있다고 가정함
quality_rating : 0.82
quality_rating : 0.37
#하지만 사용자가 quality_rating을 입력하지 않았다면 데이터 세트가 특수 값으로 항목의 부재를 나타낼 수 있음
quality_rating : -1- 특별한 값을 명시적으로 표시하려면 bool 특성을 만든다. > is_quality_rating_defined
- 원래 특성에서 특수 값으로 바꾼다.
- 유한한 값 집합을 갖는 변수 (이산 변수)의 경우 새 값을 집합에 추가하고 이 값을 사용하여 특성 값이 누락되었음을 나타낸다.
- 연속 변수의 경우 특성 데이터의 평균값을 사용하여 누락된 값이 모델에 영향을 미치지 않는지 확인한다.
업스트림 불안정성 고려
- 특성의 정의는 시간이 지나도 변하지 않으므로 문자열은 원-핫 벡터로 변환한다.
- 다른 모델에서 추론한 값을 수집하면 추가 비용이 발생한다.
#도시 이름은 일반적으로 변경되지 않음
city_id : "br/sao_paulo"
#219가 현재 상파울루를 나타내긴 하지만
#다른 모델에서 추론한 값을 수집하면 추가비용이 발생하며 해당 표현은 다른 모델에서 쉽게 변경될 수 있음
inferred_city_caluster: "219"
데이터 정리
특성 값 조정
- 조정 : 부동 소수점 특성 값을 자연 범위에서 표준 범위로 변환하는 것
- 특성 세트가 여러 특성으로 구성된 경우, 특성 조정하는 것이 이득
극한 이상점 처리
- 예제 : 캘리포니아 주택 데이터 세트의 roomPerPerson 특성
roomPerPerson : 한 지역의 총 객실 수를 해당 지역의 인구로 나누어 계산

- 극단적인 이상점의 영향을 최소화하려면 (방법1) 모든 값의 로그를 사용한다.
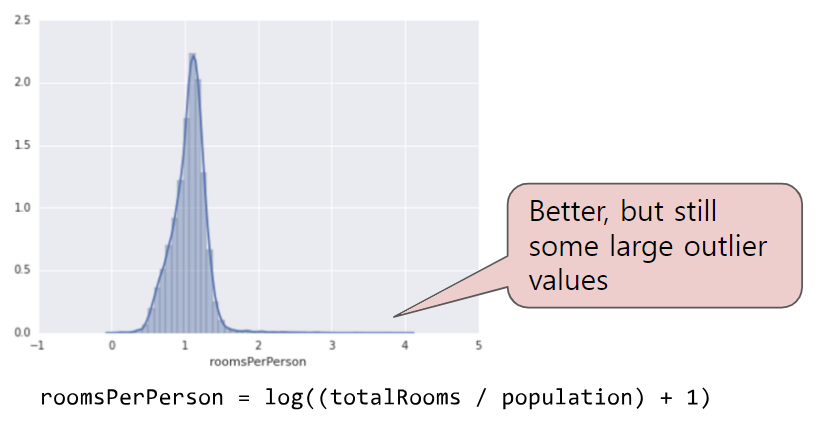
- (방법2) roomsPerPerson의 최댓값을 임의의 값(4.0)으로 간단히 제한하거나 자른다.
- 4.0보다 큰 모든 값이 이제 4.0으로 변경된다.

비닝
- 예제 : 캘리포니아 위도에 따른 주택의 상대적 분포

- latitude 는 부동 소수점 값이다.
위도와 주택 값 사이에 선형 관계가 없기 때문에 litatitue를 부동 소수점 특성으로 표현하는 것은 적합하지 않다.

- 부동 소수점 특성 대신 11개의 boolean 특성이 존재하게 된다. (LatitudeBin1, LatitudeBin2...)
- 11개의 개별 특성을 갖는 것은 불충분하므로 11원소 벡터로 통합해본다.
- 비닝을 사용하면 모델에서 각 위도에 대해 다른 가중치를 학습할 수 있다.
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]스크러빙
데이터 세트의 여러 예를 신뢰할 수 없는 이유
- 값 생략
- 중복된 예
- 잘못된 라벨 지정
- 잘못된 특성 값
히스토그램을 사용하여 데이터를 시각화해보는것도 방법
특성 교차
특성교차 : 비선형성 인코딩

파란색 : 병든 나무
주황색 : 건강한 나무
선으로 딱 나눠서 분류 불가능 > 비선형 문제
비선형 문제를 해결하려면 > 특성 교차를 만든다.
- 특성 교차 : 두 개 이상의 입력 특성을 곱하여 특성 공간에서 비선형성을 인코딩하는 합성 특성
#x1와 x2를 교차하여 x2라는 특성 교차 생성
x3 = x1x2
특성 교차의 종류
- A x B : 두 특성의 값을 곱하여 구성되는 특성 교차
- A x B x C x D x E : 특성 5개의 값을 곱하여 구성되는 특성 교차
- A x A : 단일 특성을 제곱하여 구성되는 특성 교차
특성 교차 : 원-핫 벡터 교차
- 원-핫 특성 벡터의 특성 교차 = 논리 결합
- 바이너리 특성이 있는 벡터 생성 > 원-핫 인코딩의 특성 교차를 수행하면 논리적 결합으로 해석될 수 있는 바이너리 특성을 얻게 된다.
#데이터 예시
coutnry=USA, country=France
language=English, language=Spanish
#원-핫 인코딩 수행
country:usa AND language:spanish예제 : 위도와 경도를 비닝하여 별도의 원-핫 5개 요소 특징 벡터 생성
#특정 위도 및 경도
binned_latitude = [0, 0, 0, 1, 0]
binned_longitude = [0, 1, 0, 0, 0]
#두 특성 벡터의 특성 교차 생성
#25개 요소로 구성된 원-핫 벡터(0 24개, 1 1개)
#교차에 잇는 단일 1은 위도와 경도의 특정 결합을 식별한다. > 모델이 이 결합에 대한 특정 연결을 학습할 수 있다.
binned_latitude X binned_longitude
#위도 및 경도를 더 대략적으로 비닝한다고 가정
binned_latitude(lat) = [
0 < lat <= 10
10 < lat <= 20
20 < lat <= 30
]
binned_longitude(lon) = [
0 < lon <= 15
15 < lon <= 30
]
#대략적 특성 구간을 교차하는 특성 교차 생성하면 다음과 같은 의미를 갖는 합성 특성이 생성된다.
binned_latitude_X_longitude(lat, lon) = [
0 < lat <= 10 AND 0 < lon <= 15
0 < lat <= 10 AND 15 < lon <= 30
10 < lat <= 20 AND 0 < lon <= 15
10 < lat <= 20 AND 15 < lon <= 30
20 < lat <= 30 AND 0 < lon <= 15
20 < lat <= 30 AND 15 < lon <= 30
]예제 : 모델이 다음 2개의 특성을 기반으로 개에 대한 만족도를 살펴본다고 가정
- 행동 유형 (짖는 소리, 울음, 꼭 끼는 소리 등)
- 시간
#두 특성에서 특성 교차 구축
[behavior type X time of day]- 특성 교차를 구축하면 두 기능 자체보다 훨씬 더 예측 성능이 좋은 결과를 얻게 된다.
선형 학습은 방대한 데이터에 맞게 확장되므로 대규모 데이터 세트에서는 특성 교차를 사용하는 것이 매우 효율적이다.
정규화: 단순성
L2 정규화
1. 학습 세트 및 검증 세트에 대한 손실

학습 손실은 점차 감소하지만 검증 손실은 증가하는 모델
> 모델이 학습 세트의 데이터에 대해 과적합하다는 것을 보여줌
복잡함 모델에 페널티를 적용하는 정규화라는 원칙을 사용하면 과적합을 방지할 수 있다.
- 단순히 손실을 최소화하는 것을 목표로 삼는 것이 아니라 (경험적 위험 최소화) minimize(Loss(Data | Model))
- 구조적 위험 최소화를 통해 손실과 복잡도를 최소화한다. minimize(Loss(Data | Model) + complexity (Model))
학습 최적화 알고리즘 : 모델이 데이터에 얼마나 적합한지 측정하는 손실항과 모델 복잡도를 측정하는 정규화 항의 함수가 된다.
본 강의에서 다루는 모델 복잡도
- 모델에 포함된 모든 특성의 가중치에 대한 함수로서의 모델 복잡도
모델 복잡도가 가중치의 함수인 경우, 절댓값이 높은 특성 가중치는 절댓값이 낮은 특성 가중치보다 더 복잡하다. - 0이 아닌 가중치를 사용하는 특성의 총 개수에 대한 함수로서의 모델 복잡도
모든 특성 가중치를 제곱한 값의 합으로 정규화 항을 정의하는 L2 정규화 수식을 사용하여 복잡도 수치화

이 공식에서 0에 가까운 가중치는 모델 복잡도에 거의 영향을 미치지 않지만, 이상점 가중치는 큰 영향을 미칠 수 있다.

람다 (정규화율)
람다 : 스칼라를 곱하여 정규화 항의 전반적인 영향을 조정한다.

L2 정규화를 수행하면 모델에 나타나는 효과
- 가중치 값을 0으로 유도
- 정규(종 모양 또는 가우시안) 분포로 가중치 평균을 0으로 유도
> 람다 값을 늘리면 정규화 효과가 강화된다.
2. 가중치 히스토그램
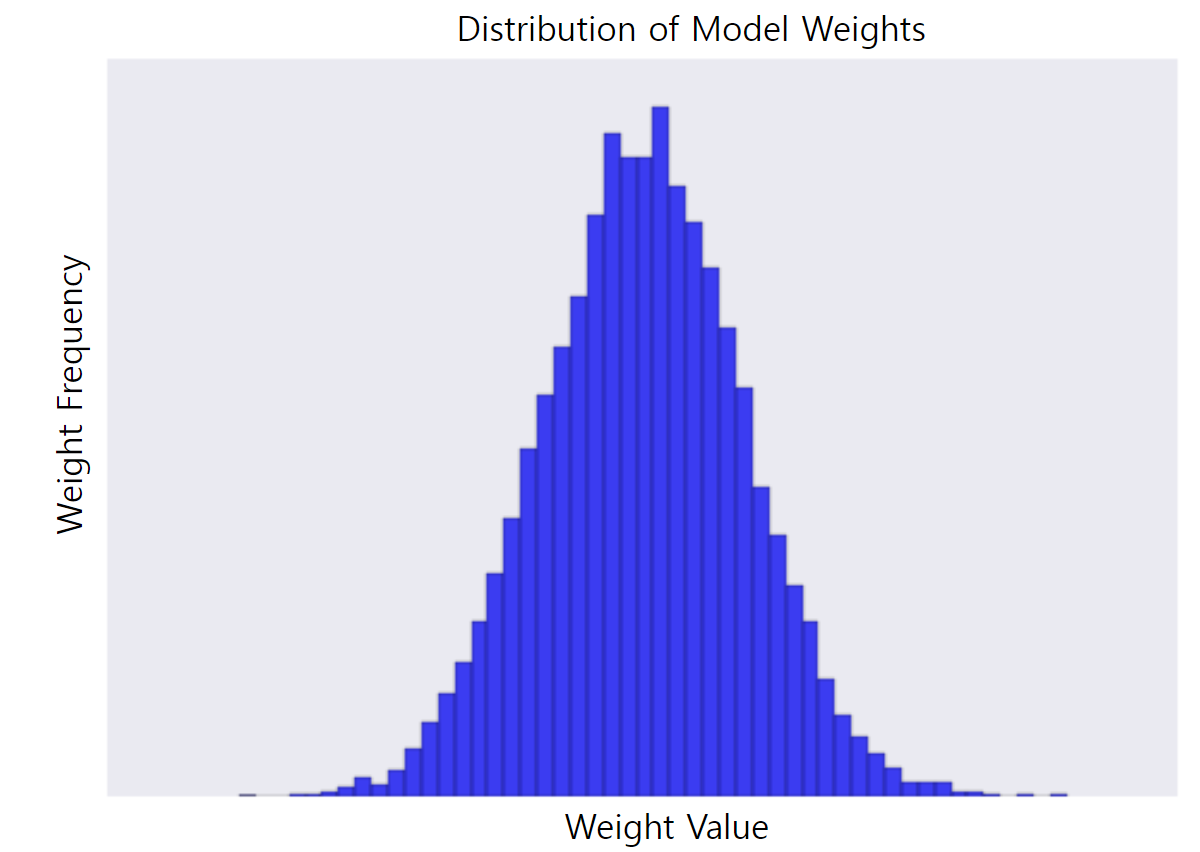
3. 더 낮은 람다 값으로 생성된 가중치의 히스토그램
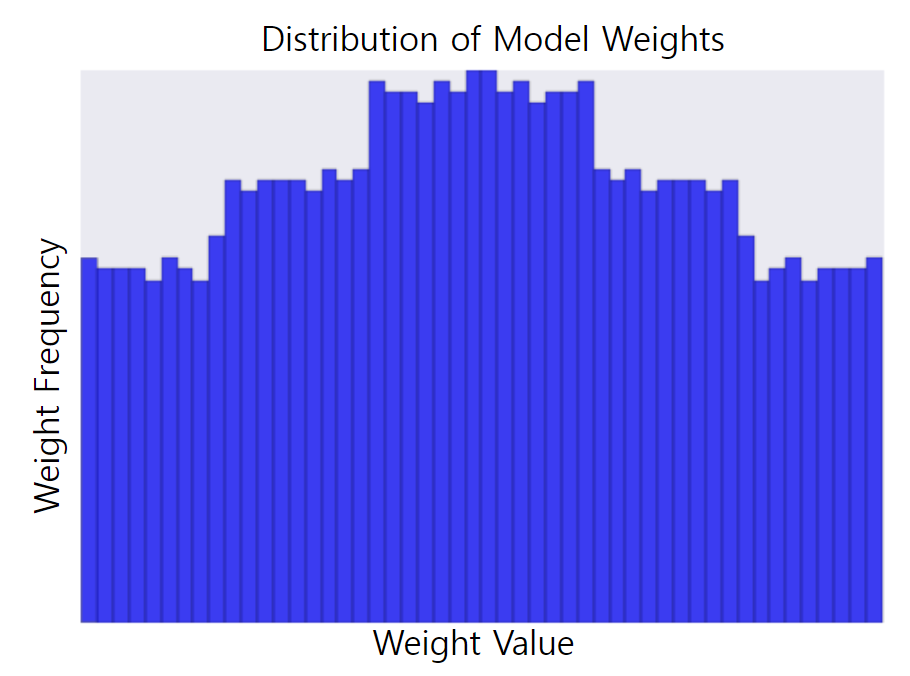
→ 람다 값을 선택할 때는 단순성과 학습 데이터 적합성 간에 적절한 균형을 맞춘다.
- 람다 값이 너무 높을 때 : 모델은 단순해지지만, 데이터가 과소적합될 수 있음 > 모델이 유용한 예측을 할 수 있을 만큼 학습 데이터에 대해 충분히 학습하지 못할 수 있음
- 람다 값이 너무 낮을 때 : 모델은 복잡해지고, 데이터가 과적합될 수 있음 > 모델이 학습 데이터의 특이성에 대해 너무 많이 학습해 새 데이터에 일반화할 수 없음
- 이상적인 람다 값 : 새로운 데이터로 잘 일반화하는 모델 생성 > 하지만 이상적인 람다 값은 데이터에 따라 달라지므로 수동 또는 자동으로 조정한다.
'Study > PBL' 카테고리의 다른 글
| Deep Fake voice recognition (0) | 2024.07.11 |
|---|---|
| Machine Learning 3 (0) | 2024.05.28 |
| Machine Learning 1 (~학습 및 테스트 세트) (0) | 2024.05.21 |
| MFCC, STFT (0) | 2024.05.20 |
| Tensorflow 강의 정리 (0) | 2024.05.15 |



