
촉촉한초코칩
06. 정렬 본문
06-1 정렬
정렬 (sorting)
- 대소 관계에 따라 데이터 집합을 일정한 순서로 줄지어 늘어서도록 바꾸는 작업
- 오름차순 (ascending order) : 키 값이 작은 데이터를 앞쪽에 놓은 것
- 내림차순 (descending order) : 키값이 큰 데이터를 앞쪽에 놓은 것
- 정렬 알고리즘의 핵심 : 교환, 선택, 삽입
정렬 알고리즘의 안전성
- 안정(stable)된 정렬 : 같은 값의 키를 가진 요소의 순서가 정렬 전후에도 유지되는 것
- 안정되지 않은 정렬 : 같은 값의 키를 가진 요소의 순서가 정렬 후에도 유지되지 않는 것
내부/외부 정렬
- 내부 정렬 (internal sorting) : 정렬할 모든 데이터를 하나의 배열에 저장할 수 있는 경우 사용하는 알고리즘
- 외부 정렬 (external sorting) : 정렬할 데이터가 너무 많아서 하나의 배열에 저장할 수 없는 경우에 사용하는 알고리즘
06-2 버블 정렬
버블 정렬
- 이웃한 두 요소의 대소 관계를 비교하여 교환을 반복한다.
- 서로 이웃한 요소에 대해서만 교환하므로 버블 정렬은 안정적이라고 할 수 있다.
- 패스 (pass) : 비교하고 교환하는 작업
- 첫 번째 패스의 비교 횟수 : n-1회
- 두 번째 패스의 비교 횟수 : n-2회 > 패스를 수행할 때마다 정렬할 요소가 하나씩 줄어들기 때문
- 패스 k회 수행 > 앞쪽의 요소 k개가 정렬된다.
버블 정렬 프로그램
//변수 i를 0부터 n-2까지 1씩 증가하며 n-1회의 패스를 수행하는 프로그램
for(i=0; i<n-1; i++) {
//a[i], a[i+1]... a[n-1]에 대해
//끝에서부터 앞쪽으로 스캔하면서 이웃하는 두 요소를 비교하고 교환한다.
}- 비교하는 두 요소의 인덱스 : j-1, j
- j 시작값 : n-1 > 배열의 끝(오른쪽) 부터 스캔
- 두 요소 (a[j-1], a[j])의 값을 비교하고 앞쪽이 크면 교환
- 그리고 j는 앞쪽으로 이동하므로 1씩 감소한다.
- 각 패스에서 앞쪽 i개의 요소 : 정렬이 끝난 상태라고 가정 > 뒷쪽부터 비교/교환하고 앞쪽부터 정렬이 끝나게 된다.
- 정렬되지 않은 부분 : a[i] ~ a[n-1]
- 한 번의 패스에서는 j 값이 i+1이 될 때까지 감소하며 비교/교환을 수행하면 된다.
- 비교하는 두 요소 중 오른쪽 요소의 인덱스는 i+1이 될 때까지 감소하고 왼쪽 요소의 인덱스는 i가 될 때까지 감소한다.
- 비교 횟수 : (n-1) + (n-2) + ... + 1 = n(n-1) / 2
- 그러나 실제 요소를 교환하는 횟수는 배열 요소값에 더 많이 영향을 받기 때문에 교환 횟수의 평균값은 비교 횟수의 절반인 n(n-1)/4회이다.
- 또한 swap 함수 안에서 값의 이동이 3회 발생하므로 이동 횟수의 평균은 3n(n-1)/4회이다.
#include <stdio.h>
#include <stdlib.h>
#define swap (type, x, y) do { type t = x; x = y; y = t; } while(0)
//버블 정렬
void bubble(int a[], int n) {
int i, j;
for(i=0; i<n-1; i++) {
for(j=n-1; j>i; j--) {
if(a[j-1] > a[j])
swap(int, a[j-1], a[j]);
}
}
}
int main(void) {
int i, nx;
int *x; //배열의 첫번째 요소에 대한 포인터
puts("버블 정렬");
printf("요소 개수 : ");
scanf("%d", &nx);
x = calloc(nx, sizeof(int)); //요소 개수가 nx인 int형 배열 생성
for(i=0; i<nx; i++) {
printf("x[%d] : ", i);
scanf("%d", &x[i]);
}
bubble(x, nx);
puts("오름차순으로 정렬했습니다.");
for(i=0; i<nx; i++)
printf("x[%d] = %d\n", i, x[i]);
free(x);
return 0;
]
알고리즘 개선 (1)
비교, 교환 작업을 개선하면서 알고리즘 개선하기
- 어떤 패스에서 요소의 교환 횟수가 0이면 더 이상 정렬할 요소가 없다는 뜻이기 때문에 정렬 작업을 멈추도록 한다.
- 변수 exchg는 패스를 시작하기 전에 0으로 초기화되고 패스에서 요소를 교환할 때마다 1씩 증가한다.
- 즉, 패스를 마쳤을 때 exchg 값 = 한 번의 패스에서 시도한 교환 횟수
- exchg 값이 0이면 정렬을 마친 것이므로 break문으로 함수를 종료한다.
void bubble(int a[], int n) {
int i, j;
for(i=0; i<n-1; i++) {
int exchg = 0; //패스에서 교환을 시도한 횟수
for(j=n-1; j>i; j--)
if(a[j-1] > a[j]) {
swap(int, a[j-1], a[j]);
exchg++;
}
if(exchg == 0) break;
}
}
알고리즘 개선 (2)
- 각각의 패스에서 비교/교환을 하다가 어떤 시점 이후에 교환이 수행되지 않는다면 그보다 앞쪽의 요소는 이미 정렬을 마친 상태이다.
- 따라서 그 이후의 패스는 정렬된 요소를 제외한 나머지 요소에 대해 비교/교환을 수행하면 된다.
void bubble(int a[], int n) {
int k = 0; //a[k]보다 앞쪽의 요소는 정렬을 마친 상태
while(k < n-1) {
int j;
int last = n-1; //마지막으로 교환을 수행한 위치 저장
for(j=n-1; j>k; j--) {
if(a[j-1] > a[j]) {
swap(int, a[j-1, a[j]);
last = j;
}
k = last;
}
}
}- last : 각 패스에서 마지막으로 교환한 두 요소 중 오른쪽 요소 (a[j])의 인덱스를 저장하기 위한 변수 > 교환을 수행할 때마다 오른쪽 요소의 인덱스 값을 last에 저장
- 하나의 패스를 마쳤을 때 last 값을 k에 대입하여 다음에 수행할 패스의 범위를 제한한다.
그러면 다음 패스에서 마지막으로 비교할 두 요소는 a[k]와 a[k+1]이 된다. - 이때 bubble 함수 시작 부분에서 k값을 0으로 초기화하는 이유는 첫 번째 패스에서는 모든 요소를 검사하기 때문이다.
06-3 단순 선택 정렬
단순 선택 정렬 (Straight Selection Sort)
- 가장 작은 요소부터 선택해 알맞은 위치로 옮겨서 순서대로 정렬하는 알고리즘
- 아직 정렬하지 않은 부분에서 값이 가장 작은 요소를 선택하고 아직 정렬하지 않은 부분의 첫번째 요소와 교환한다.
단순 선택 정렬의 교환 과정
- 아직 정렬하지 않은 부분에서 가장 작은 키의 값 (a[min])을 선택한다.
- a[min]과 아직 정렬하지 않은 부분의 첫 번째 요소를 교환한다.
//단순 선택 정렬
void selection (int a[], int n) {
int i, j;
for(i=0; i<n-1; i++) { //n-1회 반복
int min = i;
for(j=i+1; j<n; j++)
if(a[j] < a[min])
min = j;
swap(int, a[i], a[min]);
}
}단순 선택 정렬 알고리즘의 요소값을 비교하는 횟수 : (n^2 - n) / 2회
* 하지만 서로 떨어져 있는 요소를 교환하는 것이기 때문에 안정적이지 않다.
06-4 단순 삽입 정렬
단순 삽입 정렬 (Straight Insertion Sort)
- 선택한 요소를 그보다 더 앞쪽의 알맞은 위치에 '삽입' 하는 작업을 반복하여 정렬하는 알고리즘
- 단순 삽입 정렬은 2번째 요소부터 선택하여 진행한다.
- 그리고 아직 정렬되지 않은 부분의 첫 번째 요소를 정렬된 부분의 알맞은 위치에 삽입한다.
- 정렬된 부분과 아직 정렬되지 않은 부분에서 배열이 다시 구성되며 위 작업을 n-1회 반복하면 정렬을 마치게 된다.
* 알맞은 곳에 삽입?
- 선택한 요소보다 작은 요소를 만날 때까지 이웃한 왼쪽 요소를 대입하는 작업 반복
- 그러다가 선택한 요소보다 작은 요소를 만나면 해당 위치에 선택한 요소 값을 넣는다.
* 드모르간 법칙을 적용하여 조건이 모두 성립할 때까지 반복한다.
//단순 삽입 정렬
#include <stdio.h>
#include <stdlib.h>
//단순 삽입 정렬 함수
void insertion(int a[], int n) {
int i, j;
for(i=; i<n; i++) {
int tmp = a[i];
for(j=i; j>0 && a[j-1] > tmp; j--) //드모르간 법칙
a[j] = a[j-1];
a[j] = tmp;
}
}
int main(void) {
int i, nx;
int *x; //배열의 첫번째 요소에 대한 포인터
puts("단순 삽입 정렬");
printf("요소 개수 : ");
scanf("%d", &nx);
x = calloc(nx, sizeof(int)); //요소 개수가 nx인 int형 배열 생성
for(i=0; i<nx; i++) {
printf("x[%d] : ", i);
scanf("%d", &x[i]);
}
insertion(x, nx); //배열 x를 단순 삽입 정렬
puts("오름차순으로 정렬했습니다.");
for(i=0; i<nx; i++)
printf("x[%d] = %d\n", i, x[i]);
free(x);
return 0;
}* 단순 삽입 정렬은 떨어져 있는 요소들이 서로 뒤바뀌지 않아 안정적이다.
* 요소 비교 횟수와 교환 횟수 : n^2 / 2회
단순 정렬의 시간 복잡도
- 버블, 선택, 삽입 시간 복잡도 : O(n^2) > 효율이 좋지 않다.
06-5 셀 정렬
셀 정렬 (shell sort)
- 정렬할 배열의 요소를 그룹으로 나눠 각 그룹별로 단순 삽입 정렬을 수행하고, 그 그룹을 합치면서 정렬을 반복하여 요소 이동 횟수를 줄인다.
셀 정렬 과정
- 배열을 4개의 그룹으로 나누고 각 그룹별로 정렬한다.
* 4칸만큼 떨어진 요소를 모아 그룹을 4개로 나누어 정렬하는 방법 : 4-정렬
아직 정렬을 마친 상태는 아니지만, 어느저도 정렬을 마친 상태에 가까워진다. - 4-정렬을 마친 상태에서 2칸만큼 떨어진 요소를 모아 두 그룹으로 나누어 2-정렬을 수행한다.
- 마지막으로 1-정렬을 적용한다.
* h-정렬 : 셀 정렬 과정에서 수행하는 각각의 정렬
절열되지 않은 사태의 배열에 대해 단순 삽입 정렬을 그냥 적용하는 것이 아니라 조금이랃 정렬된 상태에 가까운 배열로 만들어 놓은 다음 마지막으로 단순 삽입 정렬을 수행하며 정렬을 마친다.
> 정렬해야 하는 횟수는 늘지만 전체적으로 요소 이동 횟수가 줄어들어 더 효율적인 정렬을 할 수 있다.
//셸 정렬
#include <stdio.h>
#include <stdlib.h>
//셸 정렬 함수
void shell(int a[], int n) {
int i, j, h;
for(h=n/2; h>0; h/=2)
for(i=h; i<n; i++) {
int tmp = a[i];
for(j=i-h; j>=0 & a[j]>tmp; j-=h)
a[j+h] = a[j];
a[j+h] = tmp;
}
}
int main(void) {
int i, nx;
int *x; //배열 첫번째 요소에 대한 포인터
puts("셸 정렬");
printf("요소 개수 : "):
scanf("%d", &nx);
x = calloc(nx, sizeof(int));
for(i=0; i<nx; i++) {
printf("x[%d] : ", i);
scanf("%d", &x[i]);
}
shell(x, nx);
puts("오름차순으로 정렬했습니다.");
for(i=0; i<nx; i++)
printf("x[%d] = %d\n", i, x[i]);
free(x);
return 0;
}
중분값 (h 값)의 선택
- 그룹을 나눠서 각각 정렬해야 하므로 나눈 그룹끼리는 겹치면 안 된다.
즉, h값이 서로 배수가 되지 않도록 해야 한다. 이렇게 해야 요소가 충분히 섞여 효율적인 정렬을 할 수 있다. - h는 1부터 시작하여 3배한 값에 1을 더하는 수열을 사용한다.
h의 초기값이 너무 크면 효과가 없기 때문에 배열의 요소 개수 n을 9로 나눈 값을 넘지 않도록 한다.
//셸 정렬 (버전 2)
#include <stdio.h>
#include <stdlib.h>
//셸 정렬 함수
void shell(int a[], int n) {
int i, j, h;
for(h=1; h<n/9; h = h*3+1); //h는 1부터 시작하여 9를 나눈 값을 넘지 않도록 한다.
for(; h>0; h/3) //마지막에 h의 값은 1이 된다.
for(i=h; i<n; i++) {
int tmp = a[i];
for(j=i-h; j>=0 && a[j] > tmp; j-=h)
a[j+h] = a[j];
a[j+h]= tmp;
}
}
int main(void) {
int i, nx;
int *x; //배열의 첫번째 요소에 대한 포인터
puts("셸 정렬");
printf("요소 개수 : ");
scanf("%d", &nx);
x = calloc(nx, sizeof(int));
for(i=0; i<nx; i++) {
printf("x[%d] : ", i);
scanf("%d", &x[i]);
}
shell(x, nx);
puts("오름차순으로 정렬했습니다.");
for(i=0; i<nx; i++)
printf("x[%d] = %d\n", i, x[i]);
free(x);
return 0;
}* 셸 시간 복잡도 : O(n^1.25)
* 하지만 떨어져 있는 요소를 교환해야 하므로 안정적이지 않다.
06-6 퀵 정렬
퀵 정렬 (quick sort)
- 하나의 요소를 기준으로 그 요소보다 작은 요소와 큰 요소로 두 그룹으로 나눈다.
- 이때 기준이 되는 요소를 피벗(pivot)이라고 한다.
- 가 그룹에 대해 피벗 설정과 그룹 나눔을 반복하며 모든 그룹이 1명이 되면 정렬을 마친다.
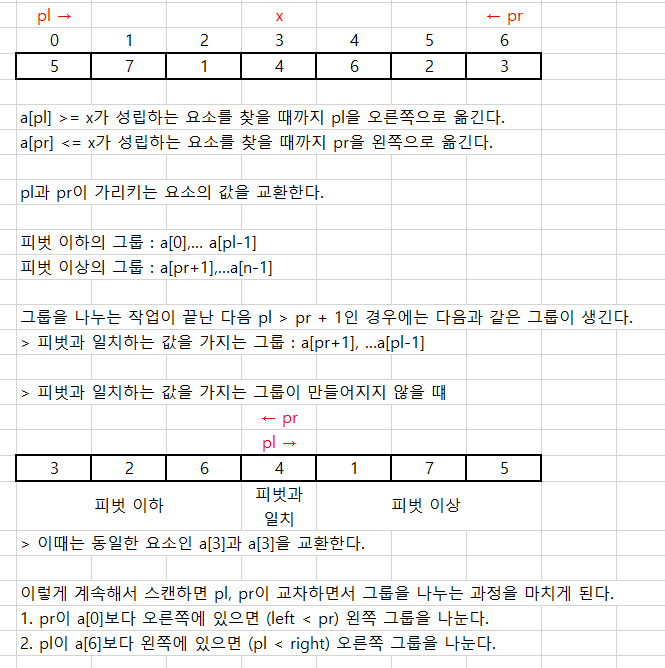
//배열을 나누는 프로그램
#include <stdio.h>
#include <stdib.h>
#define swap(type, x, y) do {type t = x; x = y; y = t;} while(0)
//배열을 나누는 함수
void partition(int a[], int n) {
int i;
int pl = 0; //왼쪽 커서
int pr = n-1; //오른쪽 커서
int x = a[n/2]; //피벗 선택 (가운데 요소)
do {
while(a[pl] < x) pl++;
while(a[pr] > x) pr--;
if(pl <= pr) { //배열 a를 피벗 x를 기준으로 나눈다.
swap(int, a[pl], a[pr]);
pl++;
pr--;
}
} while(pl <= pr);
printf("피벗의 값은 %d입니다.\n", x);
printf("피벗 이하 그룹 \n");
for(i=0; i<=pl-1; i++)
printf("%d ", a[i]);
putchar('\n');
if(pl > pr + 1) {
printf("피벗과 일치하는 그룹 \n");
for(i=pr+1; i<=pl-1; i++)
printf("%d ", a[i]);
putchar('\n');
}
printf("피벗 이상 그룹 \n");
for(i=pr+1; i<n; i++)
printf("%d ", a[i]);
putchar('\n');
}
int main(void) {
int i, nx;
int *x; //배열의 첫번째 요소에 대한 포인터
puts("배열을 나눕니다.");
printf("요소 개수 : ");
scanf("%d", &nx);
x = calloc(nx, sizeof(int));
for(i=0; i<nx; i++) {
printf("x[%d] : ", i);
scanf("%d", &x[i]);
}
partition(x, nx);
free(x);
return 0;
}* 요소 개수가 2개 이상인 그룹일 때만 left < pr, pl < right 조건이 성립된다.
재귀호출로 구현하기
//퀵 정렬
#include <stdio.h>
#include <stdib.h>
#define swap(type, x, y) do {type t = x; x = y; y = t;} while(0)
//퀵 정렬 함수
void quick(int a[], int left, int right) {
int pl = left; //왼쪽 커서
int pr = right; //오른쪽 커서
int x = a[(pl+pr)/2]; //피벗 선택 (가운데 요소)
do {
while(a[pl] < x) pl++;
while(a[pr] > x) pr--;
if(pl <= pr) {
swap(int, a[pl], a[pr]);
pl++;
pr--;
}
} while(pl <= pr);
//재귀호출!!
//만약 pr이 left보다 오른쪽에 있다면, 반으로 또 나눠서 정렬
if(left < pr) quick(a, left, pr);
//만약 pl이 right보다 왼쪽에 있다면, 반으로 또 나눠서 정렬
if(pl < right) quick(a, pl, right);
}
int main(void) {
int i, nx;
int *x; //배열의 첫번째 요소에 대한 포인터
puts("퀵 정렬");
printf("요소 개수 : ");
scanf("%d", &nx);
x = calloc(nx, sizeof(int));
for(i=0; i<nx; i++) {
printf("x[%d] : ", i);
scanf("%d", &x[i]);
}
quick(x, 0, nx-1);
puts("오름차순으로 정렬했습니다.");
for(i=0; i<nx; i++)
printf("x[%d] = %d\n", i, x[i]);
free(x);
return 0;
}
퀵 정렬 분할 과정 출력
//배열 분할 과정을 출력하는 퀵 정렬 프로그램
void quick(int a[], int left, int right) {
int pl = left; //왼쪽 커서
int pr = right; //오른쪽 커서
int x = a[(pl+pr)/2]; //피벗 선택 (가운데 요소)
int i;
printf("a[%d] ~ a[%d] : {", left, right);
for(i=left; i<right; i++)
printf("%d ", a[i]);
printf("%d}\n", a[right]);
do {
while(a[pl] < x) pl++;
while(a[pr] > x) pr--;
if(pl <= pr) {
swap(int, a[pl], a[pr]);
pl++;
pr--;
}
} while(pl <= pr);
//재귀호출!!
//만약 pr이 left보다 오른쪽에 있다면, 반으로 또 나눠서 정렬
if(left < pr) quick(a, left, pr);
//만약 pl이 right보다 왼쪽에 있다면, 반으로 또 나눠서 정렬
if(pl < right) quick(a, pl, right);
}
비재귀적인 퀵 정렬
//퀵 정렬을 비재귀적으로 구현한 프로그램
void quick(int a[], int left, int right) {
IntStack lstack; //나눌 범위의 왼쪽 끝 요소의 인덱스를 저장하는 스택
IntStack rstack; //나눌 범위의 오른쪽 끝 요소의 인덱스를 저장하는 스택
//스택 생성
//스택 용량 : right - left + 1
Initialize(&lstack, right-left+1);
Initialize(&rsatck, right-left+1);
Push(&lstack, left); //left : 0
Push(&rstack, right); //right : 6
while(!IsEmpty(&lstack)) {
//lstack에서 뺀 값을 left에 대입한 다음 그 left 값을 다시 pl에 대입한다.
int pl = (Pop(&lstack, &left), left); //왼쪽 커서
int pr = (Pop(&rstack, &right), right); //오른쪽 커서
//결과 : left와 pl은 0, right와 pr은 8이 된다. > 정렬할 배열 범위
int x = z[(left + right) / 2]; //피벗 (가운데 요소
do {
while(a[pl] < x) pl++;
while(a[pr] > x) pr--;
if(pl <= pr) {
swap(int, a[pl], a[pr]);
pl++;
pr--;
}
} while(pl <= pr);
if(left < pr) {
Push(&lstack, left); //왼쪽 그룹 범위의 인덱스 푸시
Push(&rstack, pr);
}
if(pl < right) {
Push(&lstack, pl); //오른쪽 그룹 범위의 인덱스 푸시
Push(&rstack, right);
}
}
Terminate(&lstack);
Terminate(&rstack);
}- 스택에 푸시한 값은 나눌 배열의 첫요소와 끝요소이다.
- 배열을 나누는 작업이 끝나면 왼쪽 그룹 인덱스와 오른쪽 그룹 인덱스를 푸시한다.
- 팝한 범위를 나누는 작업을 반복하며 정렬을 수행한다.
- 스택이 비면 정렬이 끝난다.
* 스택 용량 : 배열의 요소 개수로 초기화
- 요소 개수가 많은 그룹을 먼저 푸시할 때
- 요소 개수가 적은 그룹을 먼저 푸시할 때
> 비교하면 요소 개수가 적은 배열일수록 적은 횟수로 분할을 종료할 수 있다.
따라서 요소 개수가 적은 그룹을 먼저 나누면 스택에 쌓여 있는 데이터의 최대 개수를 줄일 수 있다.
스택에 넣고 꺼내는 횟수는 같지만, 스택에 쌓이는 데이터의 최대 개수는 달라진다.
피벗 선택하기
- 나눌 배열 요소 개수가 3 이상이면 임의로 3요소를 선택하고, 그중에서 중앙값이 요소를 피벗으로 선택한다.
- 나눌 배열의 처음, 가운데, 끝 요소를 정렬한 다음 가운데 요소와 끝에서 두 번째 요소를 교환한다. 피벗으로 끝에서 두번째 요소의 값(a[right-1])을 선택하여 나눌 대상의 범위를 a[left+1] ~ a[right-2]로 좁힌다.
> 나눌 그룹의 크기가 한쪽으로 치우치는 것을 피하면서 나눌 때 스캔할 요소를 3개씩 줄일 수 있다.
* 시간 복잡도 : O(n log n) > 다만 정렬할 배열의 초기값이나 피벗 선택 방법에 따라 시간 복잡도가 증가할 수도 있다.
최악의 시간 복잡도 : O(n^2)
qsort 함수 사용해서 정렬하기
| 헤더 | #include <stdlib.h> |
| 형식 | void qsort(void *base, size_t nmemb, size_t size, int(*compar)(const void *, const void *)); |
| 해설 | base : 정렬할 배열 nmemb : 요소의 개수 size : 배열 요소 크기 compar : 비교 함수 > compar에 지정한 비교 함수를 사용하여 정렬한다. compar에 전달할 비교 함수는 다음과 같은 기능을 할 수 있도록 직접 작성해야 한다. 1) 첫번째 인수가 두번째 인수보다 작은 경우에는 음수(-1)를, 같을 경우에는 0, 클 경우에는 양수를 반환한다. 2) 비교하는 두 요소가 같을 경우에는 순서를 다시 재배치하지 않는다. 같은 키 값을 가지고 있는 데이터가 2개 이상인 경우 오름차순으로 정렬되긴 하지만, 정렬 전후의 데이터가 같은 순서를 유지하지는 않는다. (안정된 배열이 아님) |
//qsort 함수 사용해서 정수 배열을 오름차순으로 정렬하기
#include <stdio.h>
#include <stdlib.h>
//int형 비교 함수 (오름차순)
//내림차순으로 정렬하려면 두번째 요소가 클 때 1, 첫번째 요소가 클 때 -1을 반환하면 된다. > 반환값을 반대로 작성
int int_cmp(const int *a, const int *b) {
if(*a < *b)
return -1;
else if(*a > *b)
return 1;
else
return 0;
}
int main(void) {
int i, nx;
int *x; //배열 첫번째 요소에 대한 포인터
printf("qsort에 의한 정렬 \n");
printf("요소 개수 : ");
scanf("%d", &nx);
x = calloc(nx, sizeof(int));
for(i=0; i<nx; i++) {
printf("x[%d] : ", i);
scanf("%d", &x[i]);
}
qsort(x, nx, sizeof(int), (int(*)(const void *, const void *))int_cmp);
puts("오름차순으로 정렬했습니다.");
for(i=0; i<nx; i++)
printf("x[%d] = %d\n", i, x[i]);
free(x);
return 0;
}ex) 구조체 배열을 정렬하는 프로그램 p244-246
06-7 병합 정렬
병합 정렬
- 배열을 앞부분과 뒷부분으로 나누어 각각 정렬한 다음 병합하는 과정을 반복하여 정렬을 수행하는 알고리즘
정렬을 마친 배열의 병합
- 배열 a와 배열 b에서 선택한 요소의 값을 비교한다.
- 더 작은 값을 배열 c(병합할 배열)에 넣는다.
- 커서를 다음 요소로 옮기고 비교, 대입 과정을 반복한다.
- 만약 한 개의 배열 요소는 모두 복사하고 다른 배열의 요소가 남아있다면 남아있는 배열의 커서를 한칸씩 다음으로 옮기면서 바로 c에 옮긴다.
#include <stdio.h>
//정렬을 마친 배열 a와 b를 병합하여 c에 저장
void merge(const int a[], int na, const int b[], int nb, int c[]) {
int pa, pb, pc = 0;
while(pa < na && pa < nb)
c[pc++] = (a[pa] <= b[pb]) ? a[pa++] : b[pb++];
while(pa < na) //a배열의 요소가 아직 남았을 때
c[pc++] = a[pa++];
while(pb < nb) //a배열의 요소가 아직 남았을 때
c[pc++] = b[pb++];
}
int main(void) {
int i, na, nb;
int *a, *b, *c;
printf("a의 요소 개수 : "); scanf("%d", &na);
printf("b의 요소 개수 : "); scanf("%d", &nb);
a = calloc(na, sizeof(int));
b = calloc(nb, sizeof(int));
c = calloc(na+nb, sizeof(int));
printf("a[0] : ");
scanf("%d", &a[0]);
for(i=1; i<na; i++) {
do {
printf("a[%d] : ", i);
scanf("%d", &a[i]);
} while(a[i] < a[i-1]);
}
printf("b[0] : ");
scanf("%d", &b[0]);
for(i=1; i<nb; i++) {
do {
printf("b[%d] : ", i);
scanf("%d", &b[i]);
} while(b[i] < b[i-1]);
}
//배열 a와 b를 병합하여 c에 저장
merge(a, na, b, nb, c);
puts("배열 a와 b를 병합하여 배열 c에 저장했습니다.");
for(i=0; i<na+nb; i++)
printf("c[%2d] = %2d\n", i, c[i]);
free(a); free(b); free(c);
return 0;
}병합에 필요한 시간 복잡도 : O(n)
병합 정렬 (merge sort)
- 정렬을 마친 배열의 병합을 응용하여 분할 정복법에 따라 정렬하는 알고리즘
병합 정렬 과정 (배열 요소 개수가 2개 이상인 경우)
- 배열 앞부분 > 병합 정렬로 정렬
- 배열 뒷부분 > 병합 정렬로 정렬
- 배열의 앞부분과 뒷부분 병합
//병합 정렬 프로그램
#include <stdio.h>
#include <stdlib.h>
static int *buff; //작업용 배열
//병합 정렬
static void __mergesort(int a[], int left, int right) {
if(left < right) {
int center = (left + right) / 2;
int p = 0;
int i;
int j = 0;
int k = left;
//재귀호출
__mergesort(a, left, center); //앞부분에 대한 병합 정렬
__mergesort(a, center+1, right); //뒷부분에 대한 병합 정렬
//배열 앞부분을 buff[0]~buff[center-left]로 복사한다.
//for문이 끝날 때 p의 값은 복사한 요소의 개수 center-left+1이 된다.
for(i=left; i<=center; i++)
buff[p++] = a[i];
//배열의 뒷부분 a[center+1]~a[right]과 buff로 복사한
//배열의 앞부분 p개를 병합한 결과를 배열 a에 저장한다.
while(i<=right && j < p)
a[k++] = (buff[j] <= a[i]) ? buff[j++] : a[i++];
//배열 buff에 남아있는 요소를 배열 a로 복사한다.
while(j<p)
a[k++] = buff[j++];
}
}
//병합 정렬 함수
int mergesort(int [], int n) {
//병합한 결과를 일시적으로 저장할 작업용 배열 buff를 생성한다.
if((buff = calloc(n, sizeof(int))) == NULL)
return -1;
//그리고 실제로 정렬 작업을 수행할 __mergesort 함수를 호출한다.
__mergesort(a, 0, n-1); //배열 전체를 병합 정렬
free(buff);
return 0;
}
int main(void) {
int i, nx;
int *x; //배열 첫번째 요소에 대한 포인터
puts("병합 정렬");
printf("요소 개수 : ");
scanf("%d", &nx);
x = calloc(nx, sizeof(int));
for(i=0; i<nx; i++) {
printf("x[%d] : ", i);
scanf("%d", &x[i]);
}
mergesort(x, nx);
puts("오름차순으로 정렬했습니다.");
for(i=0; i<nx; i++)
printf("x[%d] = %d\n", i, x[i]);
free(x);
return 0;
}- 배열 병합의 시간 복잡도 : O(n)
- 데이터의 요소 개수가 n개일 때, 병합 정렬의 단계는 log n만큼 필요하므로 전체 시간 복잡도는 O(n log n)이 되낟.
- 또한 서로 떨어져 있는 요소를 교환하는 것이 아니므로 안정적인 정렬 방법이다.
06-8 힙 정렬
힙 정렬 (heap sort)
- 힙 : '부모의 값이 자식의 값보다 항상 크다'는 조건을 만족하는 완전이진트리
- 이때 부모의 값이 자식보다 항상 작아도 힙이라고 한다. (부모-자식 요소의 관계만 일정하면 된다.)
- 힙의 가장 위쪽에 있는 루트가 가장 큰 값이 된다.
- 형제 사이의 대소 관계는 정해져 있지 않아 부분순서트리(partial ordered tree)라고도 한다.
* 완전이진트리 : 부모가 자식을 왼쪽부터 추가하는 모양. 이때 '이진'은 부모가 가질 수 있는 자식 개수가 최대 2개라는 의미이다.
힙 트리 과정
- 가장 위쪽에 있는 루트를 a[0]에 넣는다.
- 한 단계 아래 요소를 왼쪽에서 오른쪽으로 따라 간다.
- 인덱스 값을 1씩 늘리면서 배열의 각 요소에 힙의 요소를 대입한다.
부모와 자식 인덱스 사이의 관계
- 부모 : a[(i - 1) / 2]
- 왼쪽 자식 : a[i * 2 + 1]
- 오른쪽 자식 : a[i * 2 + 2]
힙 정렬
- 힙에서 가장 큰 값이 루트를 꺼내는 작업을 반복하고 그 값을 늘어놓으면 정렬을 마치게 된다.
- 즉, 선택 정렬을 응용한 알고리즘이며 힙에서 가장 큰 값인 루트를 꺼내고 남은 요소에서 다시 가장 큰 값을 구해야 한다.
- 이때 루트를 뺀 나머지 요소로 만든 트리도 힙의 형태를 유지할 수 있도록 재구성해야 한다.
루트 없애고 힙 상태 유지하기
- 루트 꺼내기
- 마지막 요소를 루트로 이동
- 자기보다 큰 값을 가지는 자식 요소와 자리를 바꾸며 아래쪽으로 내려가는 작업 반복
이때 자식의 값이 작거나 앞에 다다르면 작업이 종료된다.
힙 정렬 알고리즘
- 힙의 루트에 있는 가장 큰 값을 꺼내 배열 마지막 요소에 넣는다.
- 배열의 마지막부터 큰 값이 차례대로 대입된다.
- 변수 i를 n-1로 초기화한다. (배열 마지막 요소)
- a[0]과 a[i]를 바꾼다.
- a[0], a[1] ... a[i-1]을 힙으로 만든다.
- i 값을 1씩 줄여 0이 되면 끝이 난다. 그렇지 않으면 2번으로 돌아간다.
* 이때 초기 상태가 힙 상태가 아닐 수도 있으므로 위 과정을 적용하기 전에 먼저 배열을 힙 상태로 만들어야 한다.
배열을 힙으로 만들기 (트리가 힙이 아닐 때)
- 마지막(가장 아랫부분의 가장 오른쪽) 부분트리를 선택하여 힙으로 만들어준다.
- 바로 왼쪽 트리의 부분트리를 힙으로 만든다.
- 아랫부분 힙 정렬이 완성되면 위로 올라가며 가장 오른쪽부터 힙으로 만들어준다.
힙 정렬의 시간 복잡도
- 힙 정렬 : 선택 정렬을 응용한 알고리즘
- 단순 선택 정렬 : 정렬되지 않은 영역의 모든 요소를 대상으로 가장 큰 값을 선택한다.
- 첫 요소를 꺼내는 것만으로 가장 큰 값이 구해지므로 첫 요소를 꺼낸 다음 나머지 요소를 다시 힙으로 만들어야 그 다음에 꺼낼 첫 요소도 가장 큰 값을 유지하게 된다.
따라서 단순 선택 정렬에서 가장 큰 요소를 선택할 때의 시간 복잡도 O(n)의 값을 한 번에 선택할 수 있어 O(1)로 줄일 수 있다. - 힙 정렬에서 다시 힙으로 만드는 작업의 시간 복잡도 : O(log n)
//힙 정렬 프로그램
#include <stido.h>
#include <stdlib.h>
#define swap(type, x, y) do {type t = x; x = y; y = t;} while(0)
//배열 a 가운데 a[left] ~ a[right]를 힙으로 만드는 함수
//a[left] 이외에는 모두 힙 상태라고 가정하고
//a[left]를 아랫부분의 알맞은 위치로 옮겨 힙 상태로 만든다.
static void downheap(int a[], int left, int right) {
int temp = a[left]; //루트
int child;
int parent;
for(parent = left; parent < (right+1)/2; parent = child) {
int cl = parent * 2 + 1; //왼쪽 자식
int cr = cl + 1; //오른쪽 자식
child = (cr <= right && a[cr] > a[cl]) ? cr : cl; //큰 값 선택
if(temp >= a[child])
break;
a[parent] = a[child];
}
a[parent] = temp;
}
//요소 개수가 n개인 배열 a를 힙 정렬
//1) downheap함수를 사용하여 배열 a를 힙으로 만든다.
//2) 루트(a[0])에 있는 가장 큰 값을 빼내어
// 배열 마지막 요소와 바꾸고 배열의 나머지 부분을 다시 힙으로 만드는 과정을 반복하여 정렬 수행
void heapsort(int a[], int n) {
int i;
for(i = (n-1)/2; i>=0; i--)
downheap(a, i, n-1);
for(i=n-1; i>0; i--) {
swap(int, a[0], a[i]);
downheap(a, 0, i-1);
}
}
int main(void) {
int i, nx;
int *x; //배열 첫번쨰 요소에 대한 포인터
puts("힙 정렬");
printf("요소 개수 : "):
scanf("%d", &nx);
x = calloc(nx, sizeof(int));
for(i=0; i<nx; i++) {
printf("x[%d] : ", i);
scanf("%d", &x[i]);
}
heapsort(x, nx);
puts("오름차순으로 정렬했습니다.");
for(i=0; i<nx; i++)
printf("x[%d] = %d\n", i, x[i]);
free(x);
return 0;
}
06-9 도수 정렬
도수 정렬
- 요소의 대소 관계를 판단하지 않고 빠르게 정렬할 수 있는 알고리즘
도수 정렬 4단계 ex) 10점 만점 테스트에서 학생 9명의 점수
- 도수 분포표 만들기 : 각 점수에 해당하는 학생이 몇명인지 나타내는 도수 분포표
- 누적 도수분포표 만들기 : 0점부터 점수 n까지 몇 명의 학생이 있는지 누적된 값
- 목적 배열 만들기 : 각각의 점수를 받은 학생이 몇번쨰에 위치하는지
- 배열 복사하기
//도수 정렬 프로그램
#include <stdio.h>
#include <stdlib.h>
//도수 정렬 함수 (배열 요소값 : 0 이상 max 이하)
void fsort(int a[], int n, int max) {
int i;
//정렬을 위한 작업용 배열 f와 b 생성
int *f = calloc(max+1, sizeof(int)); //누적 도수 > 도수분포, 누적도수 넣는 배열
int *b = callof(n, sizeof(int)); //작업용 목적 배열 > 임시로 저장할 배열
//1) 도수분포표 만들기
for(i=0; i<=max; i++) f[i] = 0;
//2) 누적도수분포표 만들기
for(i=0; i<n; i++) f[a[i]]++;
//3) 목적 배열 만들기
for(i=1; i<=max; i++) f[i] += f[i-1];
//4) 배열 복사하기
for(i=n-1; i>=0; i--) b[--f[a[i]]] = a[i];
for(i=0; i<n; i++) a[i] = b[i];
free(b); free(f);
}
int main(void) {
int i, nx;
int *x;
const int max = 100; //가장 큰 값
puts("도수 정렬");
printf("요소 개수 : ");
scanf("%d", &nx);
x = calloc(nx, sizeof(int));
printf("0~%d의 정수를 입력하세요\n", max);
for(i=0; i<nx; i++) {
do {
printf("x[%d] : ", i);
scanf("%d", &x[i]);
} while(x[i] < 0 || x[i] > max);
}
fsort(x, nx, max); //배열 x를 도수 정렬
puts("오름차순으로 정렬했습니다.");
for(i=0; i<nx; i++)
printf("x[%d] = %d\n", i, x[i]);
free(x);
return 0;
}
도수 정렬 알고리즘
- 데이터 비교, 교환 작업이 없어서 매우 빠르다.
- 단일 for문만 사용하며 재귀호출, 이중 for문이 없어 효율적이다.
- 하지만 도수분포표가 필요하기 때문에 데이터의 최소값과 최대값을 미리 알고 있는 경우에만 사용 가능하다.
- 각 단계(for)에서 배열 요소를 건너뛰지 않고 순서대로 스캔하므로 같은 값에 대해 순서가 바뀌는 일이 없어서 안정적이다.
- 그러나 3단게에서 배열 a를 스캔할 때 마지막 위치부터가 아닌 처음부터 스캔하면 안정적이지 않다.
실행 순서가 바꾸면 원래 배열 (a)에서 처음에 위치한 값인 3이 a[4]에 저장되고 마지막에 위치한 값인 3이 a[3]에 저장되므로 순서가 반대로 바뀌게 된다. > 같은 값이 있을 때 값이 뒤바뀌게 되므로 마지막 위치부터 해야 한다.
'Algorithm' 카테고리의 다른 글
| 07. 집합 (0) | 2023.05.15 |
|---|---|
| [백준] 9086(문자열) c언어 (0) | 2023.05.06 |
| [백준] 27866(문자와 문자열) c언어 (0) | 2023.04.22 |
| 05. 재귀 알고리즘 (1) | 2023.04.21 |
| [백준] 10813(공 바꾸기) c언어 (0) | 2023.04.15 |
